编译原理实验
1.词法分析
1 | |
点击显示/隐藏
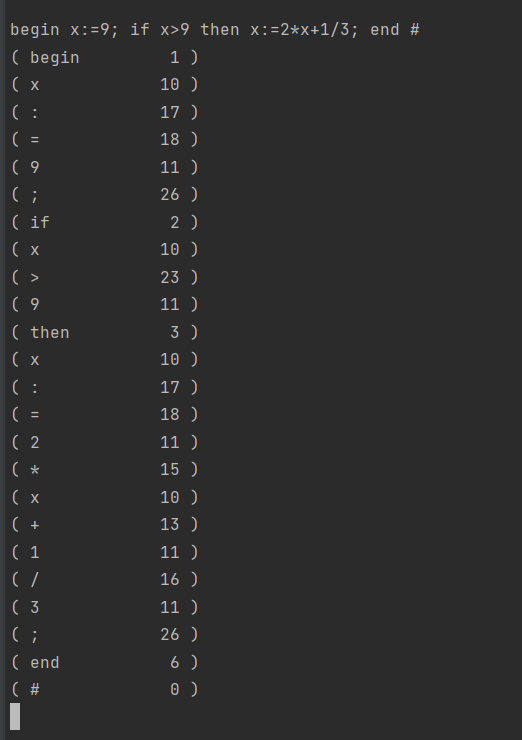
这段代码是一个简单的词法分析器(Lexical Analyzer),用于解析输入字符串并将其拆分为词法单元(Token),如标识符、数字、保留字和操作符等。词法分析器是编译器前端的一部分,它读取源代码,将其分解为有意义的基本元素,供后续的语法分析阶段使用。
程序的结构概述
- 全局变量:
prog[80]: 用来存储输入的程序字符序列,最多可容纳80个字符。token[32]: 存储当前识别的词法单元(Token),最大长度为32个字符。ch: 用来存储当前读取的字符。syn: 用来表示当前识别的词法单元的类型(如保留字、标识符、操作符等)。p: 指向prog中当前读取字符的位置。m: 指向token中存储字符的位置。n: 辅助变量,用于遍历保留字表。sum: 用于处理数字时存储数值。rwtab[6]: 保留字表,包含6个保留字:begin,if,then,while,do,end。
主要函数
main函数:- 程序从
main函数开始,首先读取用户输入的字符串并存储在prog数组中,输入以#结束。 - 然后,调用
scaner函数进行词法分析。scaner函数会不断返回词法单元,直到遇到#为止。 - 根据
syn的值,决定如何输出词法单元,分别处理数字、保留字、标识符、符号以及错误情况。
- 程序从
scaner函数(词法分析的核心部分):- 步骤 1:跳过空白字符。从
prog中读取字符,忽略空格和换行符。 - 步骤 2:识别标识符或保留字。如果字符是字母,进入标识符或保留字识别逻辑。持续读取字母或数字字符,直到遇到非字母或非数字字符。然后检查是否是保留字,如果是,设置相应的
syn值(1-6),否则syn设为 10(标识符)。 - 步骤 3:识别数字。如果字符是数字,进入数字识别逻辑,构造数值并存储在
sum中,最后将syn设为 11。 - 步骤 4:识别符号。如果是操作符或其他符号(如
+、-、<、>等),根据规则构造相应的词法单元,给出对应的syn值。部分符号(如<=、>=)需要多读取一个字符进行判断。 - 步骤 5:结束标记。如果遇到
#,将syn设为 0,表示结束。 - 步骤 6:错误处理。如果遇到无法识别的字符,将
syn设为 -1,并在main函数中输出错误信息。
- 步骤 1:跳过空白字符。从
词法单元类型 (syn) 对应表:
- 保留字(
begin,if,then,while,do,end):1-6 - 标识符:10
- 数字:11
- 操作符和符号:
<:20,<=:22>:23,>=:24=:18,==:25!:31,!=:21+:13,++:17-:14,--:29*:15/:16(:27,):28{:5,}:6;:26#:0 (结束标记)
- 错误字符:
syn = -1
程序运行过程:
输入阶段:
- 用户输入一段以
#结束的字符串,程序读取并存储在prog数组中。
- 用户输入一段以
词法分析阶段:
- 程序调用
scaner函数,逐个扫描字符并识别出相应的词法单元。 scaner会判断当前字符属于哪种类型:保留字、标识符、数字或符号,并赋值syn作为识别标志。- 程序输出对应的词法单元和
syn值,直到遇到#为止。
- 程序调用
输出阶段:
- 若为标识符或保留字,程序会输出标识符或保留字的字符串和对应的
syn值。 - 若为数字,程序会输出数值和
syn = 11。 - 若遇到错误输入,程序会提示用户输入了错误的字符串,并终止运行。
- 若为标识符或保留字,程序会输出标识符或保留字的字符串和对应的
总结:
这个程序实现了一个简单的词法分析器,能够处理保留字、标识符、数字和常见的操作符。对于初学者而言,它提供了一个理解编译器前端词法分析功能的基础框架,后续可以通过增加更多的保留字、符号或扩展错误处理来进一步完善。
1. memset(token, 0, sizeof(token)); // 清空token数组
memset 是 C 标准库中的函数,用于将内存中的某一块区域全部填充为某个值。在这行代码中:
token是一个字符数组,用来存储当前正在分析的词法单元(Token)。sizeof(token)表示token数组的大小,即 32 字节。memset(token, 0, sizeof(token))将token数组的所有元素设置为 0,也就是将整个数组清空。
在词法分析中,每次读取到新的词法单元时,需要重置 token,以确保不受之前词法单元的影响。
2. p--; // 回退一个字符
在词法分析过程中,程序会不断从 prog 数组中读取字符,p 是当前字符的指针(数组下标)。当 scaner 函数识别出一个完整的标识符、数字或符号时,通常会多读取了一个不属于该词法单元的字符(如空格、符号等),这时就需要将指针回退一个字符。
作用:
- 在识别标识符、数字等连续字符的词法单元时,
p--;确保不会跳过或漏掉字符。通过回退,可以让下次词法分析继续处理下一个未分析的字符。
例如:
- 假设输入为
"abc ",程序在读取"abc"时,会额外读取一个空格。因此需要回退一个字符,以便后续继续分析。
3. strcmp(token, rwtab[n]) // 比较 token 和 rwtab[n]
strcmp 是 C 标准库中的字符串比较函数。它用来比较两个字符串的内容是否相同。
token是存储当前识别的词法单元的字符数组。rwtab[n]是保留字表中的一个字符串,如"begin","if"等。strcmp(token, rwtab[n])会比较token和rwtab[n]是否相等。- 如果相等,返回 0,说明当前
token是保留字; - 如果不相等,返回非 0 值,说明
token不是当前比较的保留字。
- 如果相等,返回 0,说明当前
通过遍历 rwtab 数组中的保留字列表,可以判断当前 token 是否为保留字。
4. token[m] = '\0'; // 结束token字符串
C 语言中的字符串以 \0(空字符)作为结束标志。这一行代码的作用是将 token 数组的最后一位设置为 \0,从而将它标记为一个合法的 C 字符串。
- 为什么要这样做?
- 在 C 语言中,字符串是以字符数组的形式表示的,并且字符串的结尾必须用
\0来表示,否则该字符数组无法作为字符串使用。 \0确保token在后续操作(例如strcmp)中可以正确处理和比较。
- 在 C 语言中,字符串是以字符数组的形式表示的,并且字符串的结尾必须用
总结:
memset:清空token,以防残留数据影响词法分析。p--:回退一个字符,确保下次分析从正确位置开始。strcmp:比较token是否与保留字表中的某个保留字相同。token[m] = '\0:将token标记为一个以\0结尾的合法 C 字符串,确保后续字符串操作可以正确进行。
2. 语法分析
1 | |


点击显示/隐藏
这个程序实现了一个简单的 LR语法分析器,用来分析包含保留字、标识符、数字和基本算术表达式的小型程序。语法分析器通过词法分析(scaner 函数)解析输入的字符流,并基于一定的语法规则逐步匹配输入内容,检测输入是否符合语言定义的语法结构。
下面我将详细解释程序的功能和运行过程:
1. 运行过程概述:
- 程序首先读入一个以
#结尾的字符串,该字符串表示一个简化的程序。 - 程序通过词法分析(
scaner函数)将输入字符流解析成词法单元(Token),词法单元可以是标识符、保留字、数字或符号。 - 然后通过语法分析器(
lrparser函数),依据一个预定的语法规则,判断输入是否符合特定的语法。如果输入符合语法规则,输出 "Success!",否则输出相应的错误信息。
2. 主要函数介绍:
主函数 main
int main() {
p = kk = 0;
printf("\nPlease input a string (end with '#'): \n");
do {
scanf("%c", &ch);
prog[p++] = ch;
} while (ch != '#');
p = 0;
scaner(); // 读取第一个单词符号
lrparser(); // 进行语法分析
getch();
return 0;
}
p和kk初始化为 0,p是指向当前字符的索引,kk是错误标志变量。- 程序通过
scanf一次读取一个字符,直到遇到#。读入的字符保存在prog数组中。 - 调用
scaner()函数进行词法分析,从输入字符串中解析出第一个词法单元。 - 调用
lrparser()函数进行 LR 语法分析,分析输入的句子是否符合语法规则。
LR 语法分析器 lrparser
int lrparser() {
if (syn == 1) { // 'begin'
scaner(); // 读下一个单词符号
yucu(); // 调用语句序列处理
if (syn == 6) { // 'end'
scaner();
if (syn == 0) { // 成功
printf("Success!\n");
}
} else {
printf("Error: Expected 'end'!\n");
}
} else {
printf("Error: Expected 'begin'!\n");
}
return 0;
}
lrparser是语法分析器的核心。它判断输入的程序是否以begin开头,并调用yucu()函数处理语句序列。- 如果匹配到
begin后,解析到end,且end后没有其他多余的字符(即遇到#),表示语法分析成功,输出 "Success!"。 - 如果未能正确匹配到
begin或end,则输出相应的错误信息。
处理语句序列 yucu
int yucu() {
statement(); // 调用语句处理
while (syn == 26) { // ';'
scaner(); // 读下一个单词符号
if (syn != 6) { // 如果不是'end',继续处理下一个语句
statement();
}
}
return 0;
}
yucu负责处理一连串的语句。它首先调用statement()处理一条语句,然后检查是否有分号(;)分隔的多条语句。- 每当遇到分号时,继续处理下一条语句,直到遇到
end或没有更多语句。
处理单条语句 statement
int statement() {
if (syn == 10) { // 标识符
scaner(); // 读下一个单词符号
if (syn == 18) { // ':='
scaner(); // 读下一个单词符号
expression(); // 处理表达式
} else {
printf("Error: Expected ':='\n");
kk = 1;
}
} else {
printf("Error: Invalid statement!\n");
kk = 1;
}
return 0;
}
statement负责处理单个语句。它要求语句必须是 标识符(syn = 10),并且接着是赋值运算符:=(syn = 18)。- 如果语句格式正确,则调用
expression()处理右侧的表达式。 - 如果语法不正确,会输出相应的错误信息,并设置错误标志
kk。
处理表达式 expression
int expression() {
term(); // 处理项
while (syn == 13 || syn == 14) { // '+'或'-'
scaner(); // 读下一个单词符号
term(); // 处理项
}
return 0;
}
expression负责处理一个由 项(term) 组成的表达式。项之间可以由+或-连接。- 它首先调用
term()处理一个项,然后检查是否有+或-,如果有则继续处理下一个项。
处理项 term
int term() {
factor(); // 处理因子
while (syn == 15 || syn == 16) { // '*'或'/'
scaner(); // 读下一个单词符号
factor(); // 处理因子
}
return 0;
}
term处理一个由 因子(factor) 组成的项,项之间可以由*或/连接。- 它首先调用
factor()处理一个因子,然后检查是否有*或/,如果有则继续处理下一个因子。
处理因子 factor
int factor() {
if (syn == 10 || syn == 11) { // 标识符或数字
scaner(); // 读下一个单词符号
} else if (syn == 27) { // '('
scaner();
expression(); // 处理表达式
if (syn == 28) { // ')'
scaner(); // 读下一个单词符号
} else {
printf("Error: Expected ')'\n");
kk = 1;
}
} else {
printf("Error: Invalid factor!\n");
kk = 1;
}
return 0;
}
factor处理一个因子,因子可以是 标识符、数字 或 带括号的表达式。- 如果遇到
(,则递归调用expression()处理括号内的表达式,并要求最后必须遇到)。 - 如果遇到的不是标识符、数字或有效括号表达式,输出错误信息。
3. 词法分析器 scaner
void scaner() {
sum = 0;
memset(token, 0, sizeof(token)); // 清空token
m = 0;
ch = prog[p++];
while (ch == ' ') ch = prog[p++]; // 跳过空格
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) {
// 处理标识符
while ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || (ch >= '0' && ch <= '9')) {
token[m++] = ch;
ch = prog[p++];
}
p--; // 回退
syn = 10; // 默认是标识符
for (n = 0; n < 6; n++) {
if (strcmp(token, rwtab[n]) == 0) {
syn = n + 1; // 是保留字
break;
}
}
} else if (ch >= '0' && ch <= '9') {
// 处理数字
while (ch >= '0' && ch <= '9') {
sum = sum * 10 + ch - '0';
ch = prog[p++];
}
p--; // 回退
syn = 11; // 数字
} else {
// 处理运算符和分隔符
switch (ch) {
case '<': ch = prog[p++]; syn = (ch == '=') ? 22 : (ch == '>') ? 21 : 20; break;
case '>': ch = prog[p++]; syn = (ch
== '=') ? 24 : 23; break;
case ':': ch = prog[p++]; syn = (ch == '=') ? 18 : 17;break;
case '+': syn = 13; break;
case '-': syn = 14; break;
case '*': syn = 15; break;
case '/': syn = 16; break;
case '(': syn = 27; break;
case ')': syn = 28; break;
case '=': syn = 25; break;
case ';': syn = 26; break;
case '#': syn = 0; break;
default: syn = -1; break;
}
}
}scaner()函数是词法分析器,用来从输入中读取下一个词法单元并根据类型给syn赋值。- 它会处理空格,跳过空格后继续分析单词。
- 标识符:由字母和数字组成,默认
syn = 10,并检查是否为保留字(如begin、if等)。 - 数字:连续的数字序列,
syn = 11。 - 运算符和符号:通过
switch语句处理常见的运算符和分隔符(如+,-,*,:,#等)。
4. 难点解释:
- 词法分析中的回退
p--:在处理标识符或数字时,会多读入一个字符(可能是下一个单词的开始),因此需要将指针p回退一个,以便下次分析能正确从未处理的字符开始。 - 语法分析中的递归调用:语法分析器通过递归调用(如
expression调用term,term调用factor)来处理更复杂的语法结构。递归调用是匹配嵌套语法(如括号中的表达式)的常用方式。
总结:
- 这个程序通过词法分析将输入分割成词法单元,再通过语法分析判断词法单元是否符合预定的语法规则。
- 语法分析器采用递归下降法处理保留字、赋值语句、算术表达式等简单语法结构。
- 输入若符合语法规则,程序输出
Success!,否则输出错误信息。
3.语义分析
1 | |
这段代码实现了一个简易的编译器前端,完成了词法分析、语法分析,并生成了四元式中间代码,适用于一个简单的编程语言。下面从程序结构、作用和运行流程几个方面进行详细讲解:
一、程序结构
- 头文件与宏定义
- 包含了标准库(如
stdio.h,stdlib.h,string.h等)和自定义宏,定义了程序中使用的常量,如最大程序长度、符号表大小等。
- 包含了标准库(如
- 全局变量
prog和token: 存储输入的程序代码和当前处理的词法单元。quad: 用于存储生成的四元式中间代码。symbols: 记录变量的符号表,用于变量定义和检查。syn: 标识当前词法单元的类别,如关键字、标识符等。
- 辅助函数
- 词法分析函数:
scaner。 - 语法分析函数:
lrparser、statement、expression等。 - 符号表操作:
is_defined和define。 - 四元式生成函数:
emit。 - 错误处理:
error。
- 词法分析函数:
- 核心逻辑
- 实现了一个递归下降解析器,能够解析一个包含赋值语句和表达式的简单语言。
二、程序作用
- 词法分析
- 读取用户输入的程序代码,将其分割成标识符、数字、关键字、运算符等词法单元。
- 语法分析
- 检查代码是否符合指定的语法规则。例如:
- 必须以
begin开头,以end结尾。 - 每条语句的结束需要分号
;。 - 表达式和赋值的语法需要符合规则。
- 必须以
- 检查代码是否符合指定的语法规则。例如:
- 生成四元式中间代码
- 将输入程序转换为类似于汇编指令的四元式中间代码,便于进一步优化或翻译为目标机器码。
三、运行流程
用户输入代码
用户输入一个以
#结尾的程序代码字符串。示例输入:
1
2
3
4begin
a := 5;
b := a + 3;
end#
词法分析
scaner逐字符扫描输入,识别出关键字begin、标识符a、数字5等,并赋予不同的syn值。- 标识符和数字会存储在
token中,运算符直接根据符号分类。
语法分析
调用
1
lrparser对程序进行整体语法检查:
- 确保以
begin开始,调用parse_statements处理中间的语句块。 - 每个语句调用
statement检查,解析赋值表达式或简单语句。
- 确保以
生成中间代码
- 对于每个赋值语句,解析左值和右值,并生成四元式。例如:
- 输入
a := 5;会生成(1) a = 5。 - 输入
b := a + 3;会生成类似于(2) t1 = a + 3和(3) b = t1的四元式。
- 输入
- 对于每个赋值语句,解析左值和右值,并生成四元式。例如:
结果输出
语法分析完成后,程序输出所有生成的四元式。
示例输出:
1
2
3(1) a = 5
(2) t1 = a + 3
(3) b = t1
错误处理
- 遇到语法错误或未定义变量时,调用
error函数显示错误信息并终止程序。
- 遇到语法错误或未定义变量时,调用
四、运行示例分析
假设输入程序如下:
1 | |
运行步骤:
- 词法分析
- 识别出
begin、x、:=、10、;、y、:=、x、*、2、+、5、;、end、#等词法单元。
- 识别出
- 语法分析
- 首先匹配
begin和end。 - 对每个语句
x := 10;和y := x * 2 + 5;进行解析,生成对应的四元式。
- 首先匹配
- 生成四元式
- (1)
x = 10 - (2)
t1 = x * 2 - (3)
t2 = t1 + 5 - (4)
y = t2
- (1)
课程设计报告
实验报告:语义分析程序实现
目录
- 设计目的
- 设计要求
- 设计方案及算法
- 详细设计及程序源代码
- 结果分析
- 课程设计总结
一、设计目的
在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义检查,加深对语法制导翻译原理的理解。进一步掌握将语法分析所识别的语法范畴变换为中间代码(四元式)的语义分析方法,完成编译器前端开发工作。
二、设计要求
- 在语法分析程序的基础上增加语义子程序,实现对源程序的语义检查和中间代码生成。
- 输入为测试用例的源程序文件。
- 输出源程序转换的中间代码形式(四元式)并将中间代码输出到文件。
- 在检测到语法或语义错误时,能够准确报告错误信息。
- 对不同数据类型的运算对象,在算术运算前需转换为相同的数据类型。
三、设计方案及算法
设计方案
语义分析基于语法制导翻译模式,程序由以下模块组成:
- 词法分析模块:读取源代码,解析标识符、关键字、运算符、分隔符等基本单元。
- 语法分析模块:按照文法规则对词法分析结果进行解析,构建语法树。
- 语义分析模块:在语法树的基础上添加语义检查,生成中间代码(四元式)。
- 错误处理模块:发现词法、语法或语义错误时,能够准确定位并输出错误信息。
算法流程
- 词法分析:
- 逐字符读取源程序,将标识符、数字等转换为对应的记号(Token)。
- 记录每个标识符的位置,用于错误提示。
- 语法分析:
- 基于递归下降分析法或LR分析法,对输入的记号序列进行匹配,按照产生式规则构造语法树。
- 语义分析:
- 在每个产生式匹配时调用对应的语义子程序。
- 检查标识符的定义状态,未定义时输出错误。
- 根据运算生成中间代码,并记录到四元式表中。
- 生成中间代码:
- 使用四元式格式
(结果, 参数1, 操作符, 参数2)表示。 - 在遇到复合表达式时生成临时变量存储中间结果。
- 使用四元式格式
四、详细设计及程序源代码
以下为实验程序完整源代码:
1 | |
以下是每个函数及整个程序的流程图,使用Mermaid语法表示。
整体程序流程图
graph TD
Start["程序开始"]
Input["输入程序字符串"]
Scaner["词法分析器 (scaner)"]
Parser["语法分析器 (lrparser)"]
Quad["生成四元式"]
Output["输出四元式"]
End["程序结束"]
Start --> Input --> Scaner --> Parser
Parser -->|解析成功| Quad --> Output --> End
Parser -->|解析失败| Error["错误处理 (error)"] --> Endlrparser函数流程图
graph TD
LRStart["调用 lrparser"]
BeginCheck["检查是否以 'begin' 开头"]
ParseStatements["解析语句块 (parse_statements)"]
EndCheck["检查是否以 'end' 结束"]
Success["成功,程序结束"]
Error["错误处理 (error)"]
LRStart --> BeginCheck
BeginCheck -->|是| ParseStatements
BeginCheck -->|否| Error
ParseStatements --> EndCheck
EndCheck -->|是| Success
EndCheck -->|否| Errorparse_statements函数流程图
graph TD
ParseStatementsStart["调用 parse_statements"]
CheckIdent["检查是否为标识符"]
Statement["解析语句 (statement)"]
Semicolon["检查是否以 ';' 结束"]
EndParseStatements["返回"]
ParseStatementsStart --> CheckIdent
CheckIdent -->|是| Statement
CheckIdent -->|否| EndParseStatements
Statement --> Semicolon
Semicolon -->|是| CheckIdent
Semicolon -->|否| EndParseStatementsstatement函数流程图
graph TD
StatementStart["调用 statement"]
CheckIdent["检查是否为标识符"]
Define["检查并定义标识符"]
Assignment["检查赋值符号 ':='"]
Expression["解析表达式 (expression)"]
Emit["生成赋值四元式"]
EndStatement["返回"]
Error["错误处理 (error)"]
StatementStart --> CheckIdent
CheckIdent -->|是| Define
CheckIdent -->|否| EndStatement
Define --> Assignment
Assignment -->|是| Expression
Assignment -->|否| Error
Expression --> Emit
Emit --> EndStatementexpression函数流程图
graph TD
ExpressionStart["调用 expression"]
Term["解析项 (term)"]
OpCheck["检查是否有 '+' 或 '-'"]
NewTemp["生成新临时变量"]
Emit["生成四元式"]
EndExpression["返回"]
ExpressionStart --> Term
Term --> OpCheck
OpCheck -->|有| NewTemp
OpCheck -->|无| EndExpression
NewTemp --> Emit
Emit --> Termterm函数流程图
graph TD
TermStart["调用 term"]
Factor["解析因子 (factor)"]
OpCheck["检查是否有 '*' 或 '/'"]
NewTemp["生成新临时变量"]
Emit["生成四元式"]
EndTerm["返回"]
TermStart --> Factor
Factor --> OpCheck
OpCheck -->|有| NewTemp
OpCheck -->|无| EndTerm
NewTemp --> Emit
Emit --> Factorfactor函数流程图
graph TD
FactorStart["调用 factor"]
CheckType["检查类型 (标识符/数字/括号)"]
IdentCheck["检查标识符是否已定义"]
Expr["递归解析表达式"]
EndFactor["返回"]
Error["错误处理 (error)"]
FactorStart --> CheckType
CheckType -->|标识符| IdentCheck
CheckType -->|数字| EndFactor
CheckType -->|括号| Expr
CheckType -->|其他| Error
IdentCheck -->|已定义| EndFactor
IdentCheck -->|未定义| Error
Expr --> EndFactorscaner函数流程图
graph TD
ScanerStart["调用 scaner"]
SkipSpaces["跳过空格"]
Ident["处理标识符或关键字"]
Num["处理数字"]
Symbol["处理符号"]
EndScaner["返回"]
ScanerStart --> SkipSpaces
SkipSpaces --> Ident
SkipSpaces --> Num
SkipSpaces --> Symbol
Ident --> EndScaner
Num --> EndScaner
Symbol --> EndScaneremit函数流程图
graph TD
EmitStart["调用 emit"]
GenerateQuad["生成四元式并存储"]
EndEmit["返回"]
EmitStart --> GenerateQuad --> EndEmiterror函数流程图
graph TD
ErrorStart["调用 error"]
PrintMsg["打印错误信息"]
Exit["退出程序"]
ErrorStart --> PrintMsg --> Exit以下是补充的 变量检查函数 (is_defined) 和 定义变量函数 (define) 的流程图:
1 is_defined 函数流程图
graph TD
IsDefinedStart["调用 is_defined"]
Loop["遍历符号表"]
CheckMatch["检查是否匹配"]
Match["返回 true"]
EndLoop["遍历结束"]
NoMatch["返回 false"]
IsDefinedStart --> Loop
Loop --> CheckMatch
CheckMatch -->|匹配| Match
CheckMatch -->|不匹配| Loop
Loop -->|结束| EndLoop --> NoMatch2 define 函数流程图
graph TD
DefineStart["调用 define"]
CheckCapacity["检查符号表容量是否已满"]
AddSymbol["将新变量加入符号表"]
OverflowError["错误处理 (符号表溢出)"]
EndDefine["返回"]
DefineStart --> CheckCapacity
CheckCapacity -->|未满| AddSymbol --> EndDefine
CheckCapacity -->|已满| OverflowError --> EndDefine五、结果分析
- 基本语法测试
1 | |
预期输出:成功,生成赋值四元式
- 多语句测试
1 | |
预期输出:成功,生成四则运算和赋值的四元式
- 复杂表达式测试
1 | |
预期输出:成功,生成带括号的四则运算四元式
- 错误情况测试:
a. 缺少 begin
1 | |
预期输出:Error: Missing ‘begin’!
b. 缺少 end
1 | |
预期输出:Error: Missing ‘end’!
c. 未定义变量
1 | |
预期输出:Error: Variable ‘y’ is not defined!
d. 语法错误 - 不完整表达式
1 | |
预期输出:Error: Syntax error in factor!
e. 语法错误 - 缺少赋值符号
1 | |
预期输出:Error: Missing ‘:=’!
f. 括号不匹配
1 | |
预期输出:Error: Missing ‘)’!
- 连续变量定义和使用
1 | |
预期输出:成功,生成多个相关联的四元式
- 退出测试
1 | |
预期输出:Exiting…
六、课程设计总结
通过本实验,我加深了对编译原理中语法制导翻译的理解,掌握了以下技能:
- 语法制导翻译的基本实现:将语法分析与语义分析结合,完成简单编译器的前端开发。
- 中间代码生成:通过四元式表示复杂的表达式计算。
- 错误处理机制:在词法、语法和语义分析阶段均能准确定位和报告错误。
实验过程中遇到的主要问题包括:
- 对不同语法规则的处理优先级不够明确,导致初始版本生成的语法树错误。
- 在标识符定义检查中,符号表操作逻辑不完善,初期出现重复定义的问题。
改进建议:
- 增加对复杂语句(如
if-then-else结构)的支持。 - 实现更优化的符号表查找算法,提高效率。
- 在生成四元式时加入类型检查和类型转换的支持。