十种有关学习的心智模型
十种学习心智模型
[原文链接:Ten Mental Models for Learning](十种学习心智模型 - Scott H Young) Scott H. Young
心智模型是一个通用的概念,可以用来解释许多不同的现象。经济学中的供求关系、生物学中的自然选择、计算机科学中的递归或数学中的归纳证明——一旦你知道去寻找它们,这些模型就无处不在。
正如了解供求关系有助于您推理经济问题一样,了解学习的心智模型将使思考学习问题变得更加容易。
不幸的是,学习很少作为一门单独的课程来教授,这意味着这些心智模型中的大多数只有专家才知道。在这篇文章中,我想分享对我影响最大的十个,以及如果您想了解更多信息,可以更深入地挖掘的参考资料。
1. 解决问题是搜索。
Herbert Simon 和 Allen Newell 在他们的里程碑式著作*《人类问题解决*》中启动了问题解决的研究。在这篇文章中,他们认为人们通过搜索问题空间来解决问题。
问题空间就像一个迷宫:你知道你现在在哪里,你会知道你是否已经到达出口,但你不知道如何到达那里。一路上,您的行动受到迷宫墙壁的限制。
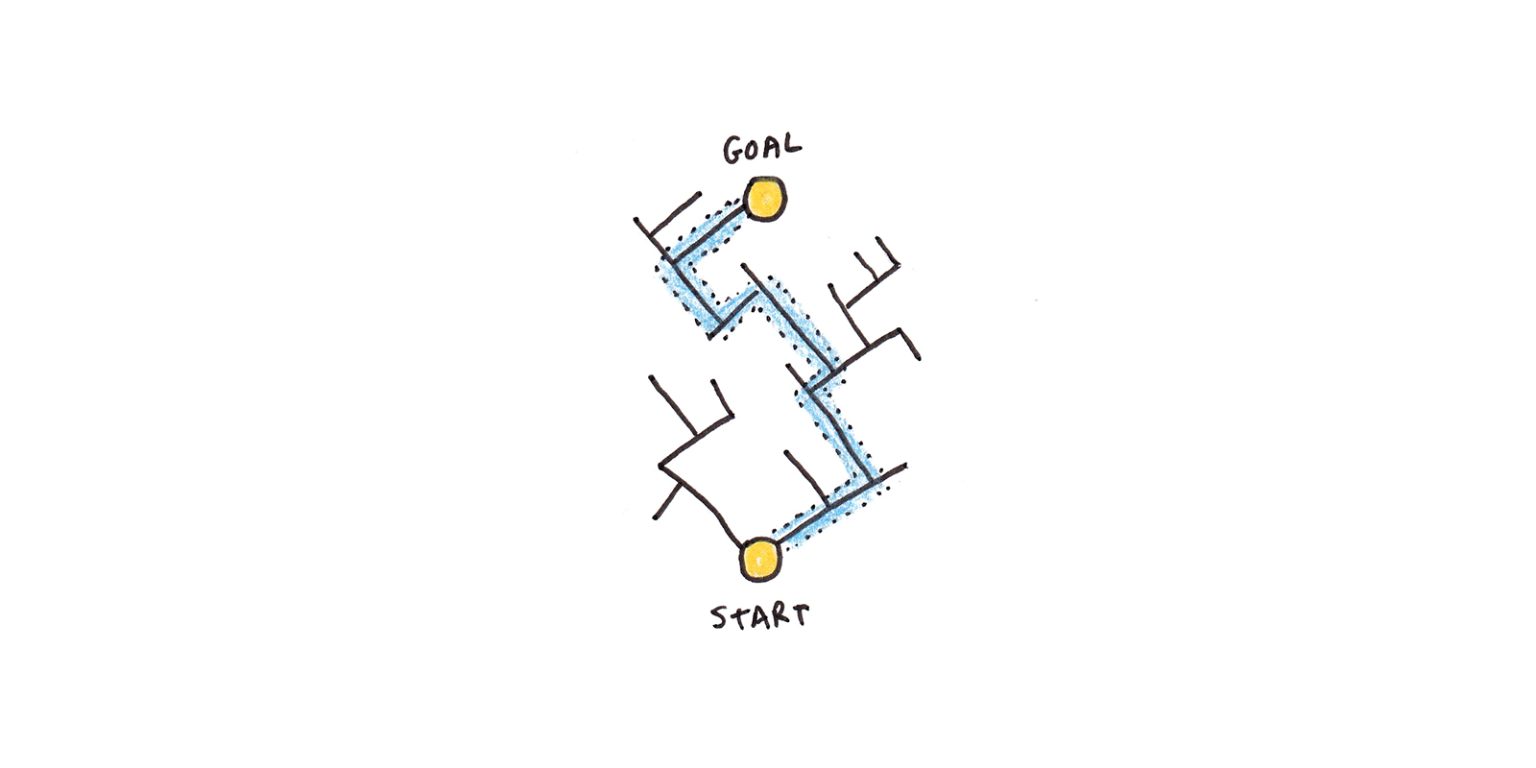
问题空间也可以是抽象的。例如,解决魔方意味着在大型问题空间的配置中移动 — 打乱的立方体是您的起点,每种颜色被隔离到一侧的立方体是出口,曲折定义了问题空间的“墙”。
现实生活中的问题通常比迷宫或魔方更广泛——开始状态、结束状态和确切的移动通常并不明确。但是,在可能性空间中寻找仍然是人们在解决不熟悉的问题时所做的事情的一个很好的特征——这意味着当他们还没有直接引导他们找到答案的方法或记忆时。
这个模型的一个含义是,如果没有先验知识,大多数问题真的很难解决。魔方有超过 43 种五重配置——如果你不聪明的话,这是一个很大的搜索空间。学习是获取模式和方法以减少暴力搜索的过程。
2. 通过检索来增强记忆力。
检索知识比第二次看到某物更能增强记忆力。测试知识不仅仅是衡量您所知道的知识的一种方式,它还会积极提高您的记忆力。事实上,测试是研究人员发现的最好的研究技术之一。
为什么检索如此有用?一种思考方式是,大脑通过只记住那些可能被证明有用的事情来节省精力。如果您手头始终有答案,则无需在内存中对其进行编码。相比之下,与检索相关的难度是您需要记住的强烈信号。
仅当有要检索的内容时,检索才有效。这就是为什么我们需要书籍、老师和课程。当内存失败时,我们回退到解决问题的搜索上,根据问题空间的大小,它可能会完全失败,无法给我们一个正确的答案。但是,一旦我们看到了答案,我们将通过检索它而不是反复查看它来了解更多。
3. 知识呈指数级增长。
你能学到多少取决于你已经知道什么。研究发现,从文本中保留的知识量取决于该主题的先前知识。在某些情况下,这种影响甚至会超过一般智力。
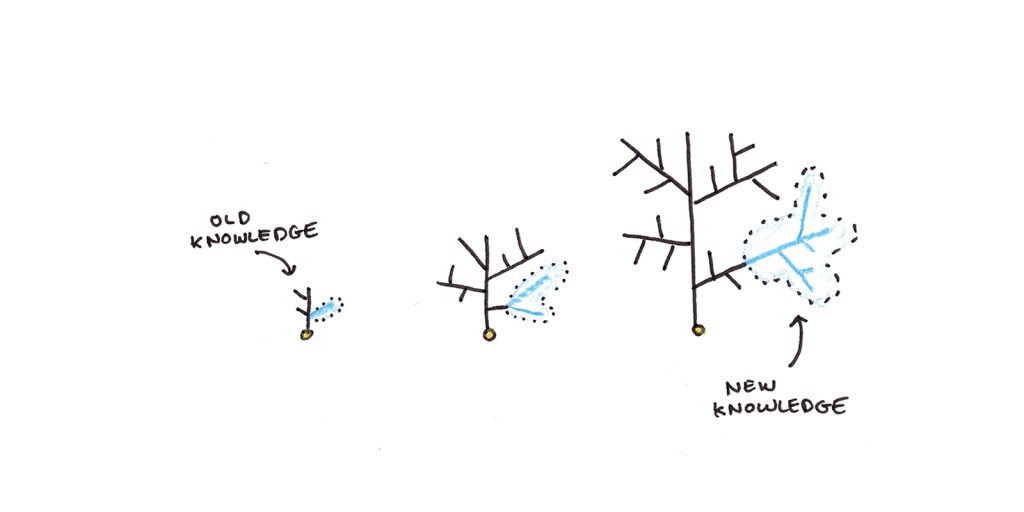
当你学习新事物时,你会将它们整合到你已经知道的事物中。此集成提供了更多钩子,供您稍后调用该信息。然而,当你对一个主题知之甚少时,你可以放置新信息的钩子就更少了。这使得信息更容易被遗忘。就像从种子中生长出的水晶一样,一旦打好了基础,未来的学习就会容易得多。
当然,这个过程是有限制的,否则知识会无限加速。尽管如此,最好记住,因为学习的早期阶段通常是最困难的,并且可能会给人一种关于某个领域内未来困难的误导性印象。
4. 创造力主要是复制。
很少有主题被误解为创造力。我们倾向于为有创造力的人注入一种近乎神奇的光环,但创造力在实践中要平凡得多。
在对重大发明的令人印象深刻的评论中,马特·里德利 (Matt Ridley) 认为创新是进化过程的结果。新发明不是完全成型地涌入世界,而是本质上是旧思想的随机突变。当这些想法被证明有用时,它们就会扩展以填补新的利基市场。
这种观点的证据来自近乎同步的创新现象。在历史上,多个没有联系的人曾无数次开发出相同的创新,这表明这些发明在被发现之前就以某种方式“接近”了可能性的空间。
即使在美术中,临摹的重要性也被忽视了。是的,许多艺术革命都是对过去趋势的明确拒绝。但革命者自己几乎无一例外地沉浸在他们所反抗的传统中。反抗任何惯例都需要意识到该惯例。
5. 技能是特定的。
转移是指在一项任务中练习或训练后,一项任务中的能力得到增强。在对迁移的研究中,出现了一个典型的模式:
- 在一项任务中练习会让你做得更好。
- 在任务中练习有助于完成类似的任务(通常是在程序或知识上重叠的任务)。
- 在一项任务上练习对不相关的任务几乎没有帮助,即使它们似乎需要同样广泛的能力,如 “记忆”、“批判性思维 ”或 “智力”。
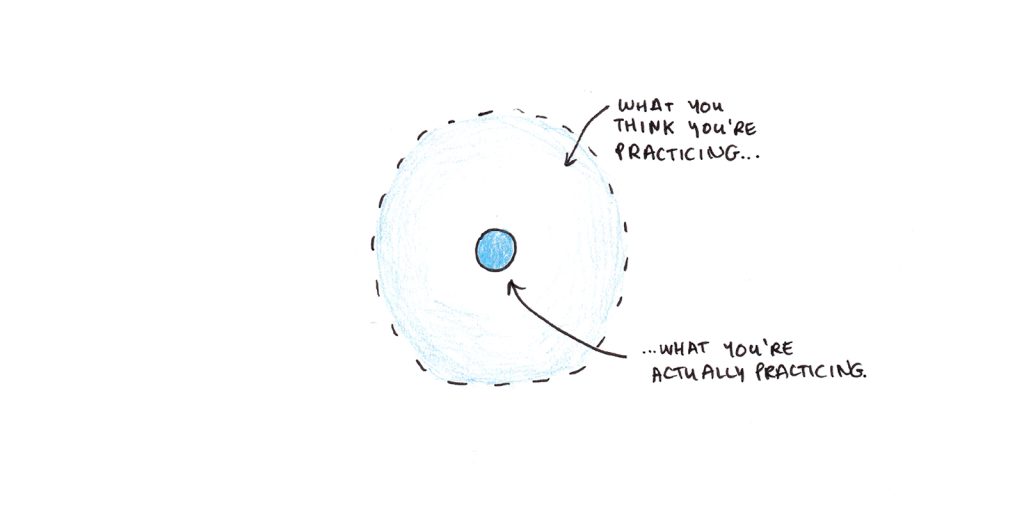
很难对迁移做出准确的预测,因为它们取决于确切地了解人类思维的工作原理和所有知识的结构。然而,在更受限制的领域中,约翰·安德森 (John Anderson) 发现,生产——以知识为基础的 IF-THEN 规则——与在智力技能中观察到的转移量形成了相当好的匹配。
虽然技能可能是具体的,但广度会产生普遍性。例如,学习外语单词仅在使用或听到该单词时才有帮助。但是如果你知道很多单词,你就可以说很多不同的东西。
同样,知道一个想法可能无关紧要,但掌握多个想法可以带来巨大的力量。每多接受一年的教育,智商就会提高 1-5 分,部分原因是学校教授的知识广度与现实生活(和智力测试)所需的知识广度重叠。
如果您想变得更聪明,没有捷径 - 您必须学习很多东西。但反之亦然。学习很多会让你比你想象的更聪明。
6. 精神带宽极其有限。
我们在任何时候都只能记住几件事。George Miller 最初将数字定为 7,正负 2 项。但最近的研究表明,这个数字更接近四件事。
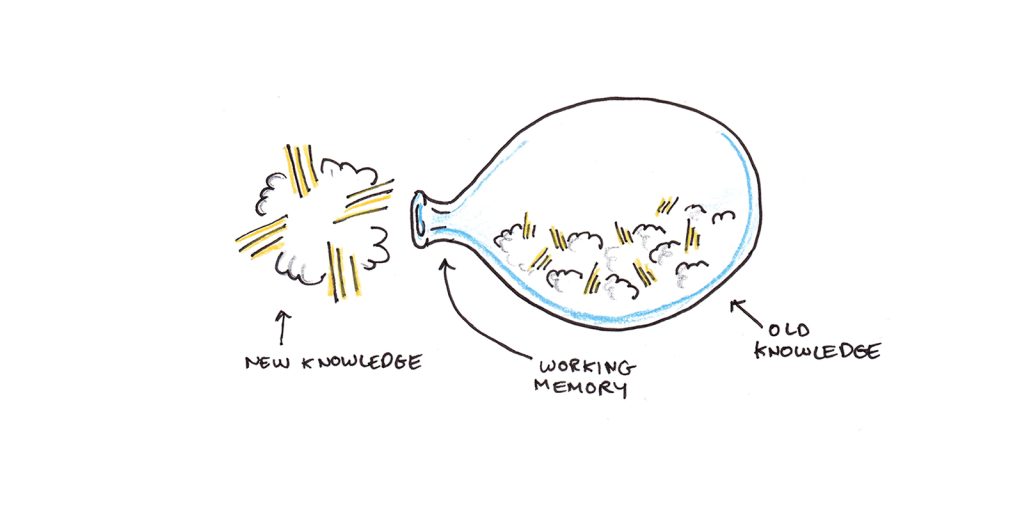
这个极其狭窄的空间是所有学习、每一个想法、记忆和经验都必须流经的瓶颈,才能成为我们长期体验的一部分。潜意识学习不起作用。如果你不专心,你就没有学习。
我们提高学习效率的主要方法是确保通过瓶颈的事物是有用的。将带宽投入到不相关的元素上可能会减慢我们的速度。
自 1980 年代以来,认知负荷理论一直被用来解释干预措施如何根据我们有限的心理带宽来优化(或限制)学习。这项研究发现:
- 对于初学者来说,解决问题可能会适得其反。新手在展示工作示例(解决方案)时表现得更好。
- 材料的设计应避免需要在页面或图表的各个部分之间翻转以了解材料。
- 冗余信息会阻碍学习。
- 如果首先分部分介绍,则可以更轻松地学习复杂的想法。
7. 成功是最好的老师。
我们从成功中学到的东西比从失败中学到的要多。原因是问题空间通常很大,并且大多数解决方案都是错误的。知道什么有效会大大降低可能性,而经历失败只能告诉你一种特定的策略不起作用。
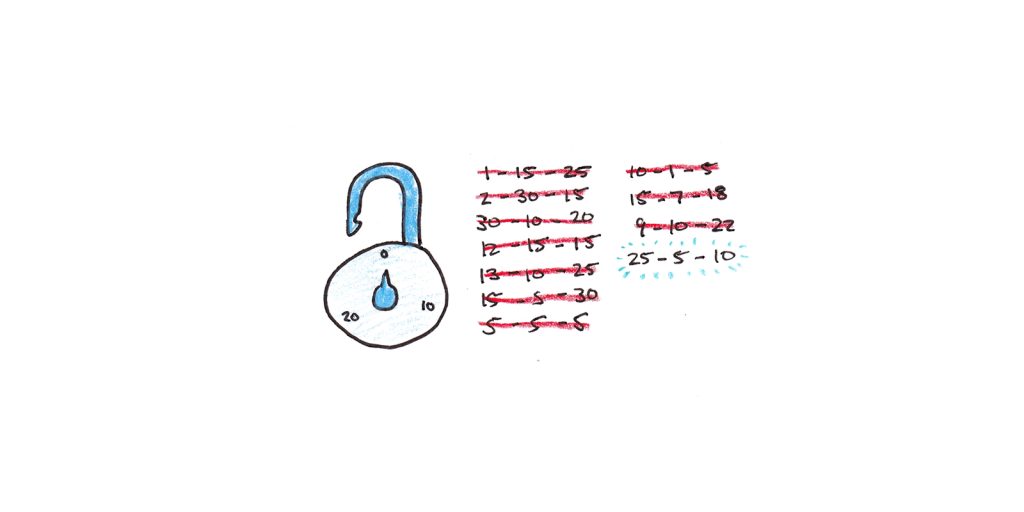
一个好的规则是在学习时以大约 85% 的成功率为目标。您可以通过校准练习的难度(开卷与闭卷、有导师与无导师、简单问题与复杂问题)或在低于此阈值时寻求额外的培训和帮助来做到这一点。如果您成功超过了这个阈值,您可能没有寻找足够难的问题——并且正在练习例行公事而不是学习新技能。
8. 我们通过例子进行推理。
人们如何进行逻辑思考是一个古老的谜题。自康德以来,我们就知道逻辑不能从经验中获得。不知何故,我们必须已经知道逻辑规则,否则一个不合逻辑的头脑永远不可能发明它们。但如果是这样的话,为什么我们经常在逻辑学家发明的那种问题上失败呢?
1983 年,菲利普·约翰逊-莱尔德 (Philip Johnson-Laird) 提出了一个解决方案:我们通过构建情境的心智模型来推理。
要检验像“所有男人都是凡人。苏格拉底是一个男人。因此,苏格拉底是凡人“,我们想象一群人,他们都是凡人,并想象苏格拉底是他们中的一员。我们通过这个检查推断出三段论是正确的。
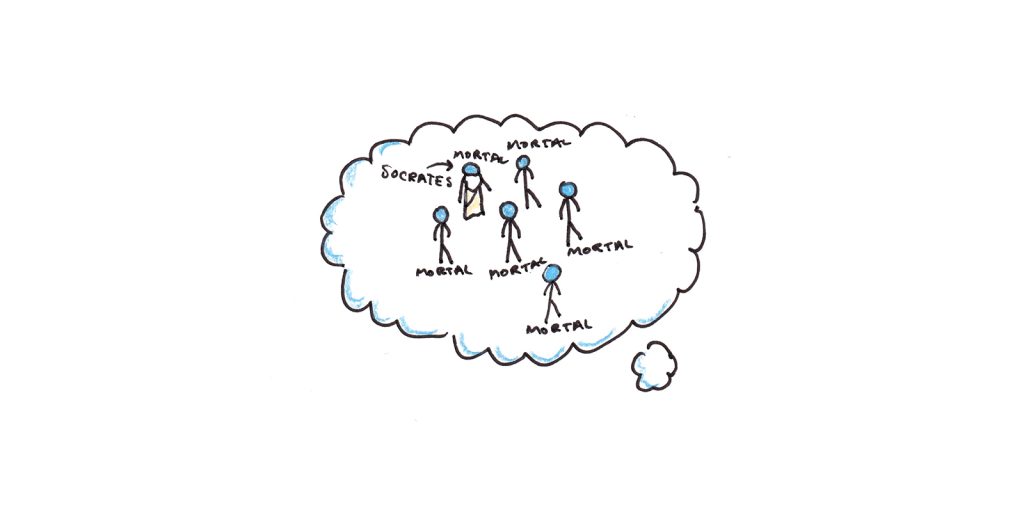
Johnson-Laird 认为,这种基于心智模型的推理也可以解释我们的逻辑缺陷。我们最挣扎的是需要我们检查多个模型的逻辑陈述。需要构建和审查的模型越多,我们犯错误的可能性就越大。
Daniel Kahneman 和 Amos Tversky 的相关研究表明,这种基于示例的推理会导致我们误以为我们回忆示例的流畅性是事件或模式的实际概率。例如,我们可能会认为适合模式 K _ _ _ 的词比 _ _ K _ 多,因为第一类的例子(例如,KITE、KALE、KILL)比第二类(例如 TAKE、BIKE、NUKE)更容易想到。
通过示例进行推理有几个含义:
- 通过示例学习通常比抽象描述更快。
- 要学习一般模式,我们需要许多示例。
- 在根据几个例子进行广泛的推断时,我们必须小心。(你确定你已经考虑了所有可能的情况吗?
9. 知识随着经验而变得不可见。
通过练习,技能变得越来越自动化。这降低了我们对这项技能的有意识意识,使其需要更少的我们宝贵的工作记忆能力来执行。想想开车:起初,使用闪光灯和刹车是经过深思熟虑的。经过多年的驾驶,您几乎不会考虑它。
然而,技能自动化程度的提高也有缺点。一是向别人传授一项技能变得更加困难。当知识变得隐性时,就更难明确地做出决策。专家经常低估“基本”技能的重要性,因为长期以来,这些技能一直被自动化,似乎在日常决策中并没有太多因素。
另一个缺点是自动化技能不太容易受到有意识的控制。当你继续以你一直的方式做某事时,这可能会导致进展停滞不前,即使这不再合适。寻求更困难的挑战变得至关重要,因为这些挑战会让您失去自动性并迫使您尝试更好的解决方案。
10. 重新学习相对较快。
在学校度过多年后,我们中有多少人还能通过毕业所需的期末考试?面对课堂问题,许多成年人羞愧地承认他们记得很少。
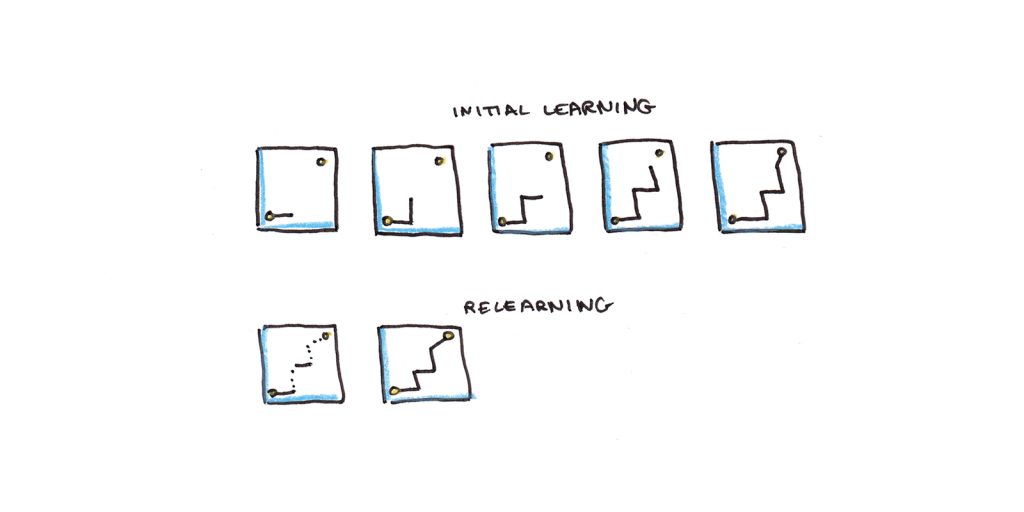
遗忘是我们不经常使用的任何技能都不可避免的命运。赫尔曼·艾宾浩斯 (Hermann Ebbinghaus) 发现,知识以指数级的速度逐渐减少——开始时最快,随着时间的推移而减慢。
然而,也有一线希望。重新学习通常比初始学习快得多。其中一些可以理解为阈值问题。想象一下内存强度范围在 0 到 100 之间。在某个阈值(例如 35)下,内存无法访问。因此,如果记忆力从 36 下降到 34,你就会忘记你所知道的。但即使是重新学习的一点点提升也能修复足以回忆起它的记忆。相比之下,新内存 (从 0 开始) 需要更多的工作。
受人类神经网络启发的联结主义模型为再学习的有效性提供了另一个论据。在这些模型中,计算神经网络可能需要数百次迭代才能达到最佳点。如果你 “抖动” 这个网络中的连接,它就会忘记正确的答案,并且不会比偶然做出更好的响应。但是,与上面的阈值解释一样,网络第二次重新学习最佳响应的速度要快得多。1
重新学习是一件令人讨厌的事情,尤其是因为与以前简单的问题作斗争可能会令人沮丧。然而,没有理由不深入和广泛地学习——即使是被遗忘的知识也可以比从头开始更快地恢复。